
Over the past several years, the application of Machine Learning, as well as its capabilities, has increased tremendously. Things that our ancestors believed could only be accomplished by a highly intelligent person are now being accomplished by robots with no human intervention.
The power of Machine Learning is very amazing. Machine Learning has made it possible to develop software that can recognise sights, sounds, and language, as well as enable humans to gain a greater understanding of technology with each passing day. If you are completely unaware of Machine Learning, then this article is for you.
In this article, we will see what is Machine Learning, a list of Machine Learning algorithms, and try to understand Machine Learning from theory to algorithms. So, let’s begin this informative guide that you would need for knowing the types of Machine Learning algorithms.
What Is Machine Learning?
Machine Learning is a kind of data analysis that automates the process of developing analytical models. Technology that enables computers to learn from data, spot patterns, and make judgments with little or no human interaction is referred to as artificial intelligence (AI).
Some examples of learning tasks include learning the function that maps the input to the output, learning the hidden structure in unlabeled data, and ‘instance-based learning,’ in which a class label is produced for a new instance (row) by comparing the new instance (row) to instances from the training data, which were previously stored in memory, and so on.
How Does Machine Learning Work?
The term “learning” is used to refer to the process by which Machine Learning algorithms learn, but it is difficult to define precisely what is meant by the term “learning” because different methods of extracting information from data exist depending on how the Machine Learning algorithm is constructed.
In general, the learning process necessitates the collection of large volumes of data that demonstrates a predicted response in response to certain inputs. Each input/response combination serves as an example, and the greater the number of instances, the simpler it is for the algorithm to learn.
This is because each input/response combination falls inside a line, cluster, or other statistical representation that defines a problem domain. It is the process of improving a model, which is a mathematically summarised representation of data so that it can anticipate or otherwise identify an acceptable response even when it gets information that it has not before seen.
The more the accuracy with which the model can generate correct replies, the greater the amount of knowledge the model has gained from the data inputs supplied. Training is the process of fitting a model to data using an algorithm, which is also known as fitting. Machine Learning is generally composed of two major components: Data & Algorithms.
- Data: Data is the information that is sent to the machine. When attempting to create a machine that can forecast the weather over the next few days, for example, you need to enter the ‘data’ from the past that includes maximum and lowest air temperatures, the speed of the wind, the quantity of rainfall, and other variables.
All of this falls under the category of ‘data,’ which your computer will learn and then analyze later. If we pay close attention to the data we have, we will always see some pattern or another in the information we have.
During a particular season, the maximum and minimum temperature ranges may be somewhat comparable; the maximum and minimum wind speeds may be slightly similar; and so on.
Machine Learning, on the other hand, allows for a more in-depth analysis of such patterns. And then it forecasts the results of the issue that we have programmed it to deal with.
- Algorithms: While data serves as the machine’s “food,” an algorithm serves as the machine’s “digestive system.” An algorithm is used to process the data. It smashes it, analyses it, permutates it, discovers the gaps, and fills in the spaces with the information it has. Algorithms are the ways that computers use to process the data that is sent to them via a computer.
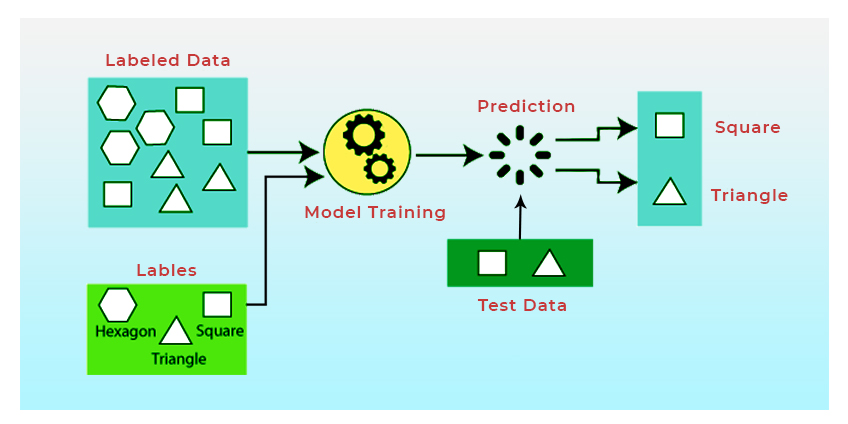
Data for Machine Learning is used for training, verifying, and testing. In the realm of computers, Machine Learning is a process, just as everything else is a process as well. To construct effective Machine Learning algorithms, you must conduct the following actions as frequently as necessary and in the order specified:

- Training: Machine Learning starts when you apply a certain algorithm to a specific set of data and then test your model against it. The training data must be distinct from any other data, but it must also be representative of the whole population. A model that does not accurately reflect the issue domain will not provide relevant results if the training data does not accurately represent the problem domain.
As part of the training phase, you will observe how the model reacts to the training data and will make adjustments as necessary to the methods you employ and how you massage the data before submitting it to the algorithm for evaluation.
- Validating: When it comes to validating, many datasets are big enough to be divided into two parts: a training component and a testing part. To verify the model, you must first train it using training data and then validate it with testing data.
Of course, the testing data must, once again, adequately reflect the issue area under consideration. In addition, it must be statistically consistent with the training data sets. Otherwise, you will not get results that accurately represent how the model will operate in practice.
- Testing: After a model has been trained and verified, it is still necessary to put it through its paces using real-world data. This stage is critical because you must ensure that the model will function properly on a bigger dataset that has not been used for either training or testing.
Every piece of data you utilise during this stage, just as you did throughout the training and validation processes, must represent the problem domain you want to engage with using the Machine Learning model.
Now we will have a glimpse of different types of Machine Learning algorithms.
Different Types Of Common Machine Learning Algorithms
These are the different types of Machine Learning algorithms:
1. Supervised Machine Learning Algorithms
In this approach, to get the output for a new set of user’s inputs, a model is trained to predict the outcomes by utilising an old set of inputs and a known set of outputs that are related to the old set of inputs. In other words, the system takes advantage of the examples that have already been utilised.
A data scientist instructs the system on how to find the characteristics and variables that should be analysed by the system. When these models are finished training, they compare the new findings to the previous results and update their data appropriately to enhance the prediction pattern.
For example, if there is a basket full of fruits, the model will be able to categorise the fruits according to the requirements that were previously provided to the system, such as colour, shape, and size of the fruits. In supervised Machine Learning algorithms, there are two strategies to choose from, and the methodology used to construct a model is determined by the sort of data it will be working with (covered in the next section).
Techniques Used In Supervised Machine Learning Algorithms
a. Machine Learning Regression Algorithms
When applied to a given dataset, this approach may be used to predict a numeric value or a range of numeric values based on the relationship between variables discovered in the dataset. For example, estimating the price of a property a year from now based on the present price, total size, location, and the number of bedrooms would be an example of forecasting.
Another example is forecasting the temperature of a room in the following hours based on the volume of the room and the temperature at the time of the prediction.
b. Machine Learning Classification Algorithms
Classification algorithms Machine Learning are employed when the input data can be classified based on patterns or labels, which is the case. Take, for example, an email classification system that can distinguish between legitimate and junk emails, or a face identification system that analyses patterns to forecast the output.
For the sake of summarising, the regression approach should be utilised when predictable data is in large quantities, and the classification technique should be used when predictable data is concerned with predicting an outcome.
Algorithms That Use Supervised Learning
These are the Machine Learning algorithms that use the supervised learning method:
- Linear Regression
- Logistic Regression
- Random Forest
- Gradient Boosted Trees
- Support Vector Machines (SVM)
- Neural Networks
- Decision Trees
- Naive Bayes
2. Unsupervised Machine Learning Algorithms
Unlike traditional training methods, this technique does not need the model to be trained on historical data; in other words, there is no “teacher” or “supervisor” to give the model past instances. By supplying any combination of inputs and related outputs, the system is not educated in any way. Instead, the model will learn and forecast the output based on its observations, which will be collected over time.
Consider the following scenario: you have a basket of fruits that have not been labelled or given any parameters. Color, size, and form are the only characteristics that the model will learn and arrange.

Source
Techniques Used In Unsupervised Machine Learning Algorithms
a. Clustering
It is a way of splitting or grouping the data in a particular data set based on similarities between the data sets in question. Data is analysed to create groups or subsets based on significant separations between them.
Clustering is utilized to detect the inherent grouping that exists within the unlabeled data that is available. The use of the clustering concept may be seen in digital image processing, where the approach is used to divide an image into discrete sections while also detecting the picture border and the object.
b. Dimension Reduction
Numerous circumstances may exist in a particular dataset, each of which requires data to be segmented or classed. These are the characteristics that each data element has, and they may or may not be unique.
When a dataset has an excessive number of such characteristics, the process of separating the data becomes complicated. A method known as a dimensional reduction may be used to address these types of difficult circumstances. This approach is a procedure that reduces the number of variables or features in a given dataset without sacrificing any of the critical information.
This is accomplished via the use of a procedure known as feature selection or feature extraction. The usage of Email Classification may be regarded as the most successful use of this approach to date.
c. Anomaly Detection
This technique is also known as outlier identification or anomaly detection. It is the discovery of unusual things, events, or observations that raise concerns because they are considerably different from the bulk of the data that is the goal of anomaly detection.
Discovering a structural fault, identifying typographical mistakes, and diagnosing medical concerns are all examples of how to use this term.
d. Neural Networks
A neural network is a framework that allows several different Machine Learning algorithms to collaborate and analyse large amounts of complicated data at the same time. The Neural Network is composed of three components that are required for the building of the model.
Neurons are referred to as “units.” Connections or parameters are two different things. There is a broad variety of uses for neural networks, including coastal engineering, hydrology, and medicine, where they are being used to diagnose certain forms of cancer.

3. Semi-Supervised Machine Learning Algorithms
Semi-supervised algorithms, as the name implies, are a combination of both supervised and unsupervised algorithms in a single algorithm. In this case, both labelled and unlabelled instances are present, and in many semi-supervised learning situations, the number of unlabelled examples is greater than the number of labelled examples.
Classification and regression are two examples of semi-supervised algorithms that are often used. The algorithms used in semi-supervised learning are typically extensions of previous approaches, and the machines that have been trained in the semi-supervised method make assumptions when dealing with unlabeled data, which is common in Machine Learning.
4. Reinforcement Machine Learning Algorithms
During this sort of learning, the machine gains knowledge from the information it has received. It continuously learns and improves its present talents by incorporating input from the environment in which it is operating. In this technique of learning, the machine learns the proper output by repeating the process over and again.
The machine understands what is good and incorrect based on the reward it receives from each repetition. It knows this because it is programmed to do so. This repetition continues indefinitely until the whole range of possible outputs has been covered.
These were the types of Machine Learning algorithms. Now we will have a glimpse of top Machine Learning Algorithms.
Most Popular Machine Learning Algorithms
These are the best Machine Learning algorithms:
1. Linear Regression
It is a Machine Learning method based on supervised learning, and it is known as Linear Regression (LR). When a dependent variable is paired with one or more independent variables, Linear Regression models the connection between the two. When dealing with scalar and exploratory variables, linear regression is the most often utilised technique.
It is used to assess the degree to which a linear connection exists between a dependent variable (scalar) and one or more independent variables (exploratory). When attempting to forecast the value of a dependent variable, a single independent variable is employed to do so. This is one of the most basic Machine Learning algorithms.
2. Logistic Regression
You must have heard the name of Logistic Regression in every Machine Learning algorithms cheat sheet. When the dependent variable is binary, the Logistic Regression method is utilised. In the field of statistics, it is the approach of choice for binary classification issues. First and foremost, it is critical to understand whether to use linear regression and when to utilise logistic regression in a given situation.
It is a specific example of linear regression in which the target variable has a categorical character, as opposed to ordinal. The dependent variable is represented by the log of the odds. It is also known as the logistic function. The sigmoid function, also known as the logistic function, produces an ‘S’ shaped curve that may be used to transfer any real-valued integer to any value between 0 and 1.
3. Support Vector Machine (SVM)
Machine Learning is primarily concerned with predicting and categorising data. To do this, you need to have a collection of Machine Learning algorithms that you may use based on the dataset. SVM is one of the Machine Learning algorithms. The concept is straightforward: draw a line or a hyperplane over the data, dividing it into several groups of information.
The Support Vector Machine (SVM) is a supervised Machine Learning technique that may be used to solve classification and regression problems in both classification and regression problems. In practice, it is most often utilised in classification difficulties. Your database is transformed using SVM, which then calculates the best border between the potential outputs.
4. Decision Trees
Decision trees are decision assistance tools that make use of a tree-like representation of the choice-making process and the potential repercussions of making a certain decision. It addresses the consequences of events, the costs of resources, and the usefulness of actions.
Decision Trees are diagrams that look similar to algorithms or flowcharts but include just conditional control statements and no other logic. Decision trees are a strong Machine Learning approach for classification and regression that may be used in many situations. The classification tree performs operations on the target to determine if it was heads or tails.
5. Random Forests
As a Machine Learning approach, Random Forests is an ensemble learning technique that is used for classification, regression, and other operations that is dependent on a large number of decision trees during the training phase. In addition to being quick and versatile, they also provide a robust strategy for mining large amounts of high-dimensional data, and they are an extension of the classification and regression decision trees we discussed previously.
Overall, ensemble learning may be characterised as a model that produces predictions by aggregating the predictions of several independent models. The ensemble model has the advantage of being more flexible and having less bias and variation.
6. K-Nearest Neighbours
In Machine Learning, the K- closest neighbour (kNN) method is a straightforward supervised learning approach that may be used to address both classification and regression issues.
KNN saves existing inputs and classifies new inputs using the same measure, i.e. the distance function, as the existing inputs. KNN has found widespread use in statistical estimation and pattern recognition, among other fields.
7. K-Means Clustering
K-means clustering is one of the most straightforward and widely used unsupervised Machine Learning methods available. The K-means approach locates k number of centroids and then assigns each data point to the cluster that is closest to it while keeping the centroids as small as feasible. It is a kind of clustering algorithm.
The ‘means’ in K-means refers to the average of the data, which is equivalent to locating the centroid. The K-means technique begins with the first set of centroids that are picked at random and are used as the starting points for each cluster. The programme then conducts iterative (repetitive) computations to optimise the locations of the centroids in each cluster.
It terminates the process of constructing and optimising clusters when the centroids have stabilised or when a predetermined number of iterations have been completed.
8. Naive Bayes
Naive Bayes is my favourite Machine Learning classifier since it is really effective and widely used. Naive Bayes is a family of algorithms in and of itself, including methods for both supervised and unsupervised learning included in the family. Naive Bayes classifiers are a set of classification algorithms based on Bayes’ Theorem that is used to identify patterns in data.
It is not a single algorithm, but rather a group of algorithms that are all based on the same underlying premise, namely that every pair of characteristics being classed is independent of the other pair of features.
Practical Bayesian Optimization Of Machine Learning Algorithms:
- Sort news stories regarding technology, politics, or sports into one of the three categories.
- An investigation of social media sentiment.
- Facial recognition software is becoming more popular.
- As with Netflix and Amazon, recommendation systems are used.
- Spam filtering is a feature of several email clients.
9. Principal Component Analysis (PCA)
Now, this one, principal component analysis, may not be the greatest contender in the algorithm category, but it is unquestionably the most practical Machine Learning approach available. PCA makes use of orthogonal transformation, which changes a collection of correlated variables into a set of uncorrelated variables to calculate correlation coefficients.
It is used to describe the variance-covariance structure of a group of variables by using linear combinations of the variables in question. It is also the most extensively used tool in exploratory data analysis and predictive modeling, according to the Statistical Software Institute.
The basic concept underlying PCA is to discover a small selection of axes that summarises a large amount of data. Consider the following scenario: we have a dataset consisting of a collection of automobile characteristics: size, color, number of seats, number of doors, size of trunk, circularity, compactness, radius, and so forth. This is one of the best Machine Learning algorithms for prediction.
Machine Learning Algorithms: Future Of Computing
Machine Learning should ultimately be created as a tool to assist in the advancement of humanity. A common belief is that automation and Machine Learning constitute a danger to employment and human labour. This is a widely held belief.
Keep in mind that Machine Learning is just a technology that has grown to make people lives easier by lowering the amount of personnel required and by providing improved efficiency at lower prices and in a shorter amount of time.
We hope this article on the best Machine Learning algorithms cleared your doubts related to Machine Learning.

